Building Single Page Applications (SPA) improves the user experience and increases performance of websites for customers. Unfortunately, these applications cause issues when those urls are rendered on social media sites such as Facebook. This article describes the steps necessary to enable Facebook URL sharing of an AngularJS application that is hosted on Amazon S3. Unfortunately, this solution requires the use of an extra EC2 instance to run an Apache Web Server. The advantage of this though is that the overall solution can be generally cheaper than using a service such as Prerender.
The Problem: Facebook + AngularJS = 🙁
Sites such as Facebook rely on metadata present on the page to render the pretty links that are displayed inline in news feeds and posts.
When the Facebook crawler hits your SPA html page though, chances are the meta content that Facebook looks for has not been rendered since it would require an AJAX request to populate the data. This post provides a potential solution to the problem that does not involve the user of a third-party service.
The Solution
The solution to this problem requires multiple steps. The biggest change required is the need to use an Apache Web Server running on EC2. This would be in addition to the S3 bucket to serve the content. This will allow crawler redirection, such as those from Facebook, Twitter, and Google, to pre-rendered static content they can easily consume while allowing normal requests to be serviced by the S3 bucket.
1. Create the EC2 Server
First we will spin up a new EC2 server on Amazon AWS. Since this will be just a web server and server side rendering for crawlers, use a small instance.
Once the box has started, ssh into the box and install the following services:
sudo apt-get install apache2 php5 php5-curl
With Apache and PHP installed we can create access to our pre-rendered content. This assumes that since you have an AngularJS application that your data is served by a web service API. We’ll leverage the API to create the pre-rendered content and populate the meta data. We’ll explore this in a separate article
We’ll need to create a new site conf file. The following shows what the contents of the file should look like:
<VirtualHost *:80>
ServerName sitename
RewriteEngine On
LogLevel alert rewrite:trace6
RewriteCond %{HTTP_USER_AGENT} (facebookexternalhit/[0-9]|Twitterbot|Pinterest|Google.*snippet)
RewriteRule pet/(\d*)$ https://serverip/index.php?id=$1 [NE,P]
RewriteRule /(.*) https://bucket.s3-website-us-east-1.amazonaws.com/$1 [P]
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
The sitename, serverip, and bucket values (the bold text above) along with the S3 bucket path should be replaced with the values you require. The index.php will be replaced with the php page you will be creating.
Ensure to enable the site config and ensure mod_rewrite and mod_proxy are turned on:
a2ensite sitename.conf
a2enmod rewrite
a2enmod proxy
2. Update S3 Configuration
In your S3 bucket properties there will be a setting for Redirection rules. The following image should help you locate this:
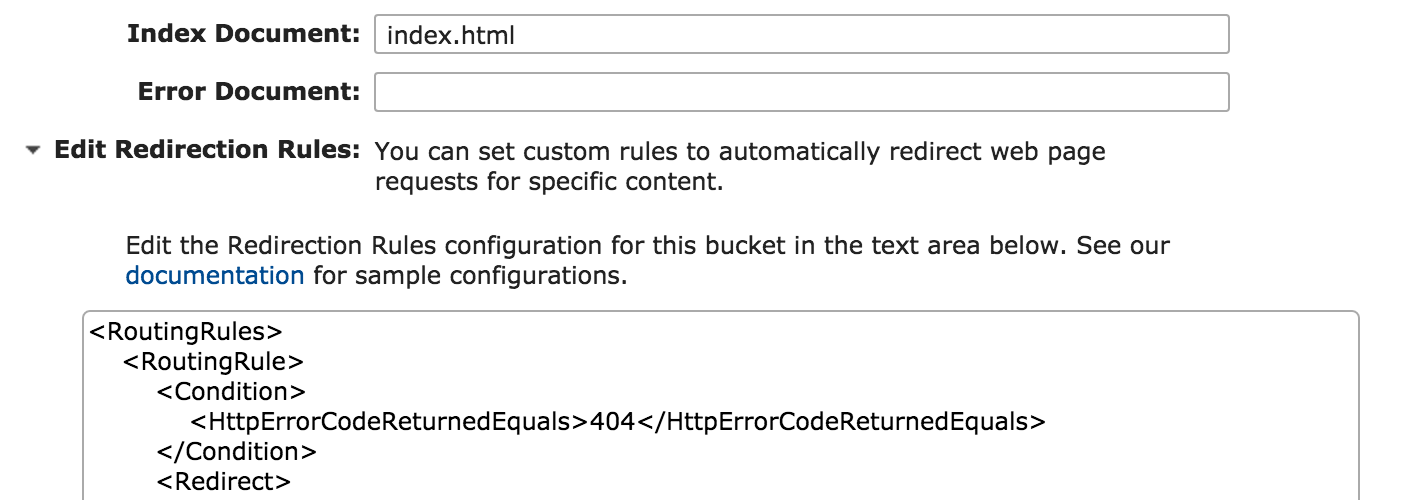
Once you locate the redirection rules we’ll be adding in a new config value. Since we’re using html5Mode for Angular, when we pull up a page a 404 Error will mostly occur given the fact that routes outside of the index route don’t exist. The configuration is as follows:
<RoutingRules>
<RoutingRule>
<Condition>
<HttpErrorCodeReturnedEquals>404</HttpErrorCodeReturnedEquals>
</Condition>
<Redirect>
<HostName>sitename</HostName>
<ReplaceKeyPrefixWith>#!/</ReplaceKeyPrefixWith>
</Redirect>
</RoutingRule>
</RoutingRules>
The redirection rule above will allow us to take those expected 404s and translate them back to hash urls which can then be parsed by the base Angular app. The Apache server rule above has been created to allow this to occur as well.
3. Update the Angular App
With the Apache Web Server configured to switch between the app and the static PHP content for crawlers and the S3 bucket configured to handle the url path scheme, the last thing we need to do is update the Angular application to handle the passed in hash url routes that will come due to the redirection rule of the S3 bucket. Do to how the Angular code gets processed, this change requires two updates: a new script tag in the head of the index.html and then an update to the run block.
In the index.html the url needs to be stored. This will allow the url to be processed by Angular later on. If this is not done ahead of time the Angular routing kicks in and the expected route is lost. Because of this fact, we toss a new script tag in the header to be pre-processed before Angular kicks in.
<script>
if(location.hash) {
window.redirectUrl = location.hash.substring(2);
}
</script>
This adds a variable that we can gain access to later in the Angular application. With this variable in our index run block we can then add the following lines:
if($window.redirectUrl) {
$location.path($window.redirectUrl);
}
Note: Access to the redirectUrl variable is handled through the $window service variable not the window object directly. This requires $window to be injected but is more Angular-ish.
Summary
Making content accessible on social media is extremely important for multiple reasons and it’s unfortunate the web crawlers cannot do a better job. Until the crawlers get their act together, this provides a least an alternative solution to make sure your content is visible and actionable on sites like Facebook and Twitter.
References
https://www.michaelbromley.co.uk/blog/171/enable-rich-social-sharing-in-your-angularjs-app